The scope of the project was to develop a model for an IDS from the ground up trying various machine learning algorithms. We used CIC 2018, CIC 2019 and HIKARI as our network traffic data. We used different datasets to simulate unseen traffic instead of using a train-test-split and holding the model’s hand.
Algorithm
Choosing the correct algorithm was no easy task. First we had to run each of the algorithms with a simple train-test split. This is a method where you divide the data frame into two sections; a larger training set, and a smaller testing set. The idea is to analyze with each respective algorithm on the training set and then compare the resulting classifications with the unseen testing data. We used the SKlearn library for our machine learning algorithms. From SKlearn we experimented with Decision Tree (DT), Random Forest (RF), K Nearest Neighbor (KNN), Multi-Layer Perceptron (MLP), and Support Vector Machine (SVM). In later sections [1-5] I will dive more into each algorithm and how they work. With these algorithms the weights change on every iteration, therefore changing the outcome of the classifier. To get a more accurate read for how each algorithm performs this task we ran each algorithm 10 times and calculated the median for each score: Accuracy, F1-Score, Recall, and Precision. This way any outliers would not affect the overall score of the algorithm.
Evaluation
In the realm of machine learning, several evaluation metrics play a crucial role in assessing the performance of algorithms. Accuracy, F1-Score, Recall, and Precision are commonly used metrics that provide valuable insights into the effectiveness of classification models. Accuracy refers to the proportion of correctly classified instances out of the total number of instances in the dataset. It provides a general overview of the model’s overall correctness. F1-Score combines precision and recall, taking into account both false positives and false negatives. It balances the trade-off between precision (the ability to correctly identify positive instances) and recall (the ability to identify all positive instances). Recall measures the model’s ability to correctly identify positive instances from the entire set of actual positive instances. Precision, on the other hand, measures the proportion of correctly identified positive instances out of all instances classified as positive. It assesses the algorithm’s precision in identifying positive cases without considering false negatives. These metrics collectively aid in evaluating and comparing the performance of different machine learning algorithms.
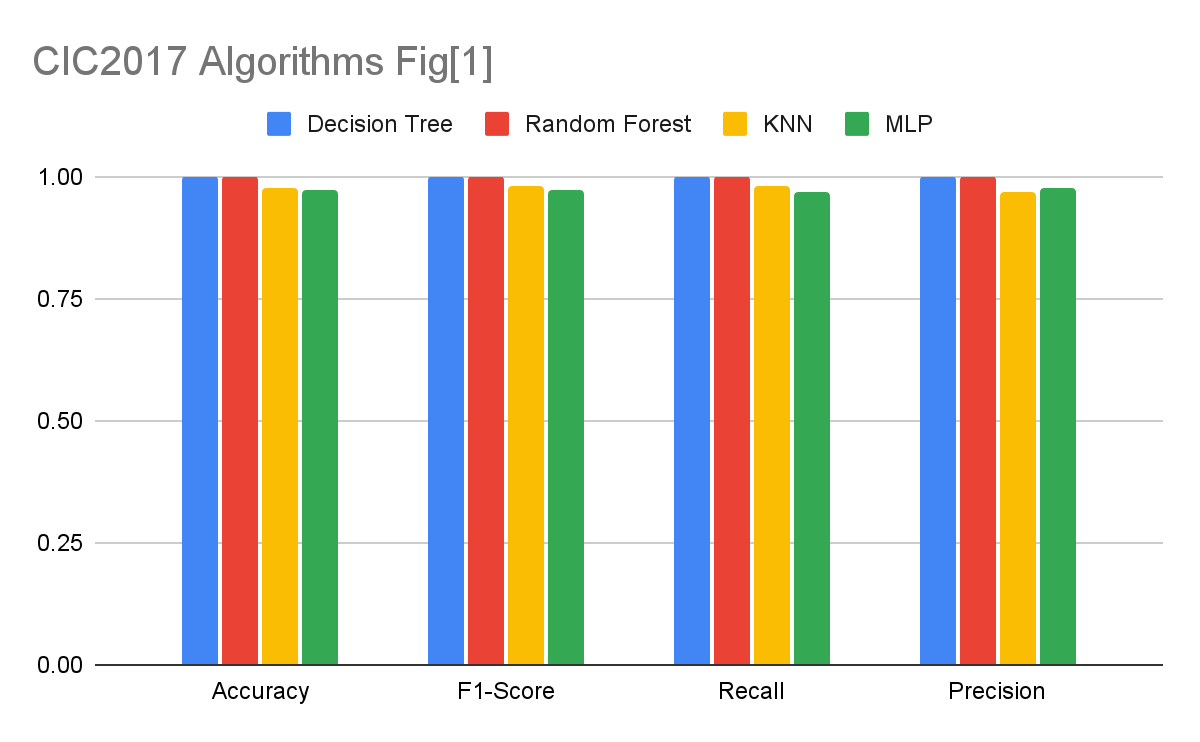
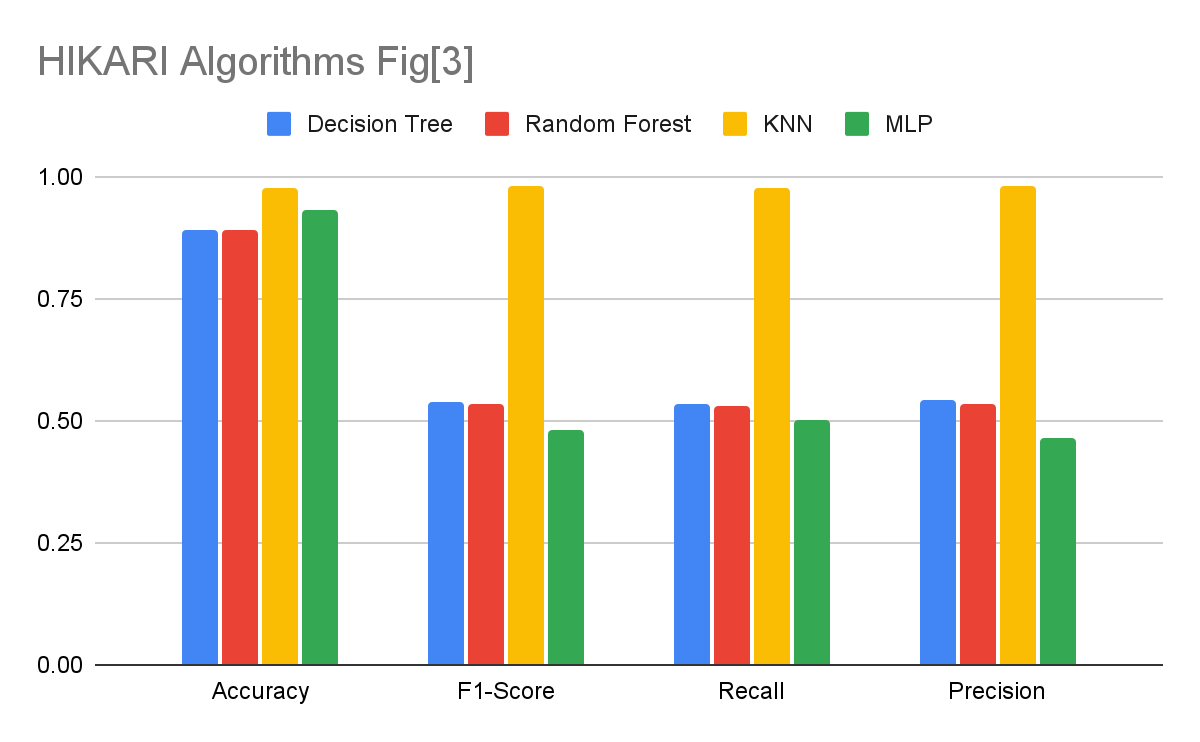
In both Figures [1] and [2] there are very good results from all algorithms except for SVM. SVM was not included because of the run time. After running the SVM algorithm on CIC2018 for over 2 hours we had to end it because it would not be viable as an IDS due to the model training time. Figure [3] has some less convincing scores. This is because the data set used was the HIKARI set. We are developing a DoS traffic IDS where in CIC2017 and CIC2018 the only traffic is DoS or normal while HIKARI is made up of XMRIGCC CryptoMiner and Bruteforce-XML traffic apart from the normal traffic. The attack traffic is not directly comparable to DoS but we included this dataset to see how these algorithms would perform detecting CryptoMiners and Bruteforce. There is an issue with the method of the tests on this data set. The features were modified to fit the same criteria as the CIC data sets. The features needed to predict HIKARI’s attacks may lie in the features removed. Accuracy, as a standalone metric, can be misleading in certain scenarios and may not provide a comprehensive evaluation of a model’s performance. The example you provided with the store theft is an excellent illustration of this limitation. In the given scenario, there were 10 people, and only one of them stole something. If we assume that you guessed zero thefts, you would be correct for nine out of the ten people. This means your accuracy would be 90%. However, accuracy alone doesn’t provide the complete picture because it fails to account for the specific class we are interested in predicting (the thefts, in this case). In situations where the classes are imbalanced, like in this example, accuracy can be misleading. In the case of theft detection, the objective is to identify the one person who stole, rather than simply classifying the majority as non-thieves. In such cases, other metrics like precision, recall, and the F1-score become more informative.
Analysis
Moving past the train-test splits, we tested how each algorithm would perform training a model with the CIC2017 data set and then applying that model to the CIC2018 data set. The reason we took this route was to simulate the application of an IDS. In the real world, an IDS will be seeing traffic it has never seen before. Training on one dataset and testing on another involves using completely separate datasets for training and testing. This approach is often employed when the availability of additional independent datasets is feasible or when evaluating the model’s performance on a different distribution is of interest. It helps assess the model’s ability to handle variations and changes in the data distribution. The key distinction between these two approaches lies in the source of the testing data. In a train-test split, testing is performed on a subset of the original dataset, providing a more immediate evaluation of the model’s performance on similar data. In contrast, testing on a separate dataset introduces the model to entirely new and independent data, enabling a broader assessment of its classification capabilities.
With the application of this new method, we discovered that MLP and KNN are the only two that show promising results to be further analyzed. Both Random Forest and Decision tree scored below 0.5000 on every metric outside of accuracy as seen in Figure [4]
| Figure [4] | DT | RF | KNN | MLP |
| Accuracy | 0.7266 | 0.6965 | 0.9667 | 0.8483 |
| F1-Score | 0.4208 | 0.4105 | 0.9667 | 0.8328 |
| Recall | 0.4997 | 0.4790 | 0.9667 | 0.8944 |
| Precision | 0.3657 | 0.3592 | 0.9668 | 0.8208 |
Inside this table shows the outputs for each metric for the tests using CIC2017 to create the model and applying the model to CIC2018. For KNN the hyper-parameters did not need to be modified very much. The ‘n_neighbors’ was set to five. This variable is the number of neighboring points of data that it takes to influence what to classify itself as. Say there were 7 people near you. Four of them like pancakes and three of them like waffles. With ‘n_neighbors’ set to five, you will likely like pancakes. However, if the two people who liked waffles were closer in proximity to you and you set ‘n_estimators’ to just three, you would likely like pancakes. Moving onto MLP, this algorithm needed more work as the initial results were good but not great, like KNN. For MLP I used three hyper parameters: ‘Hidden_layer_sizes’, ‘solver’, & ’batch_size’. MLP is a neural network, which has the ability for us to modify the number of layers and neutrons on each layer (hidden_layer_size). The solver parameter determines the optimization algorithm used to update the weights in the MLP model during training. ‘adam’ refers to Adaptive Moment Estimation, which is a popular optimization algorithm that combines ideas from both gradient descent and momentum methods. And finally, ‘batch_size’ controls the number of samples used in each iteration of the training process.
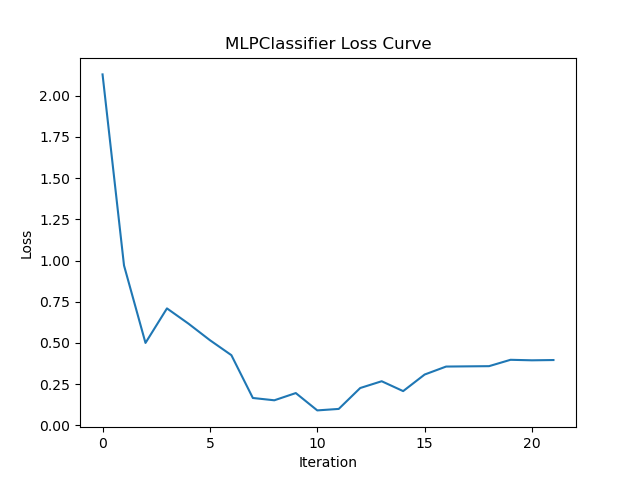
In Figure [5] is the graph of the Loss Curve created by the MLP model. When MLP is going through each iteration it calculates the loss, or measure of error. As the algorithm progresses, the loss should decrease until the change in loss over time is so small that the function stops.
Model Creation
One of the last functions used in this project is Pickles. Pickles is an object serializer, it exports data into a file that can be stored for later use. The importance of Pickles is it allows us to train with one dataset and then save that model. Every time you run an algorithm like MLP, there are weights assigned randomly from the start. If an IDS trained itself every time it was booted up there could be days where it is dialed in and others where it has a hard time detecting anything. So by saving the model, you will see the same results every time you apply it to the same data. The model used in Figure [5] is ‘MLPmodel001.pkl’ which will produce the same output when applied to CIC2018 multiple times.